Serving Multi-LoRA Models
Introduction
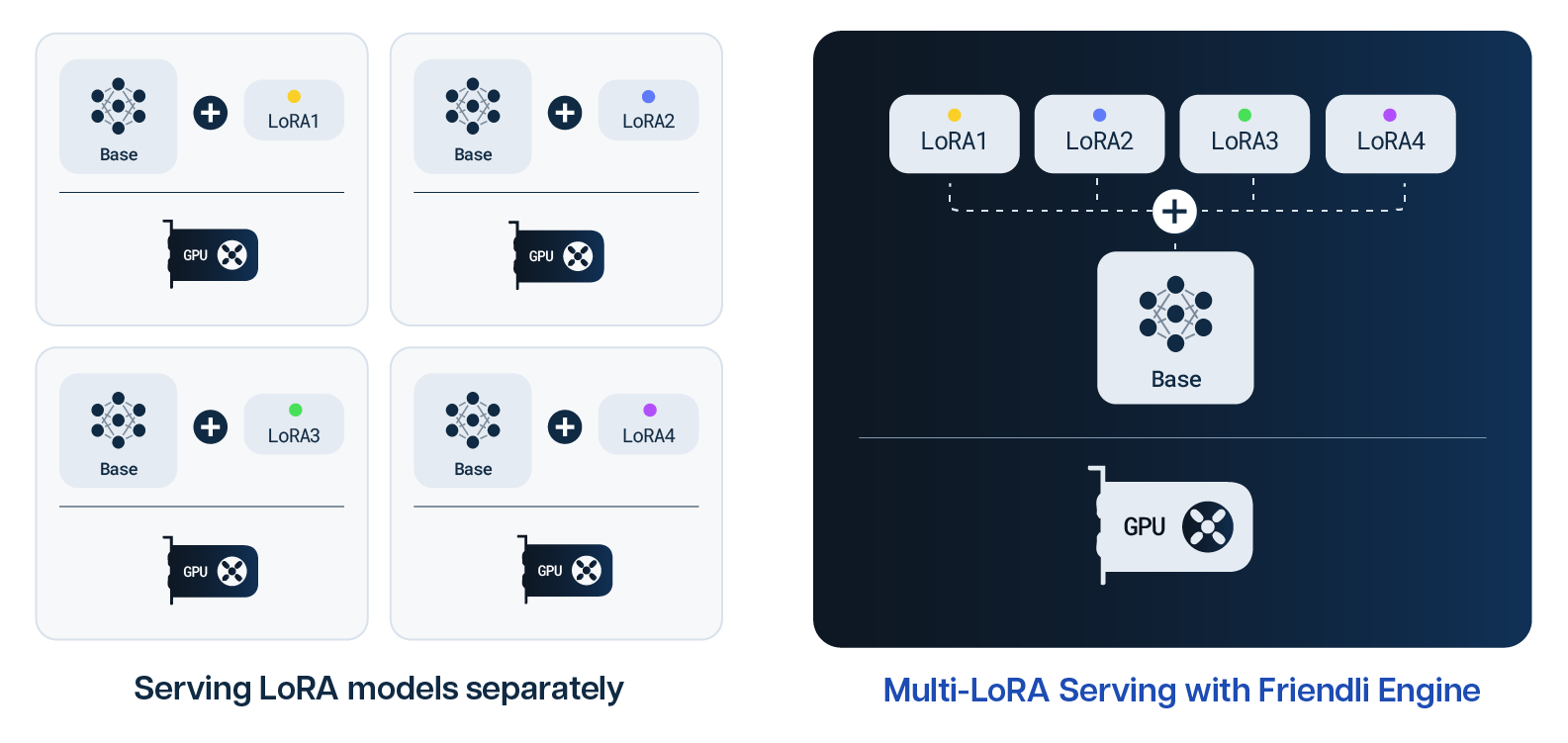
In a world where the demand for highly specialized AI capabilities is surging, the ability to deploy multiple customized large language models (LLMs) without additional GPU resources represents a significant leap forward. The Friendli Engine introduces an innovative approach to this challenge through Multi-LoRA (Low-Rank Adaptation) serving, a method that allows for the simultaneous serving of multiple LLMs, optimized for specific tasks without the need for extensive retraining. This advancement opens new avenues for AI efficiency and adaptability, promising to revolutionize the deployment of AI solutions on constrained hardware. This article provides an overview of efficient serving Multi-LoRA models with the Friendli Engine.
Prerequisite
huggingface-cli should be installed in your local environment.
pip install "huggingface_hub[cli]"
Downloading Adapter Checkpoints
For each adapter model that you want to server, you have to download in your local storage.
export ADAPTER_MODEL1="" # Hugging Face model name of the first adapter
export ADAPTER_MODEL2="" # Hugging Face model name of the second adapter
export ADAPTER_MODEL3="" # Hugging Face model name of the third adapter
export ADAPTER_DIR=/tmp/adapter
huggingface-cli download $ADAPTER_MODEL1 --include "adapter_model.safetensors" "adapter_config.json" --local-dir $ADAPTER_DIR/model1
huggingface-cli download $ADAPTER_MODEL2 --include "adapter_model.safetensors" "adapter_config.json" --local-dir $ADAPTER_DIR/model2
huggingface-cli download $ADAPTER_MODEL3 --include "adapter_model.safetensors" "adapter_config.json" --local-dir $ADAPTER_DIR/model3
...
If an adapter's Hugging Face repo does not contain adapter_model.safetensors checkpoint file, you have to manually convert adapter_model.bin into adapter_model.safetensors.
You can use the official app or the python script for conversion.
Launch Friendli Engine in Container
When you have prepared adapter model checkpoints, now you can serve the Multi-LoRA model with Friendli Container.
In addition to the command for running the base model, you have to add the --adapter-model argument.
--adapter-model: Add an adapter model with adapter name and path. The path can be Hugging Face hub's name.
# Fill the values of following variables.
export HF_BASE_MODEL_NAME="" # Hugging Face base model name (e.g., "meta-llama/Llama-2-7b-chat-hf")
export FRIENDLI_CONTAINER_SECRET="" # Friendli container secret
export FRIENDLI_CONTAINER_IMAGE="" # Friendli container image (e.g., "registry.friendli.ai/trial")
export GPU_ENUMERATION="" # GPUs (e.g., '"device=0,1"')
export ADAPTER_NAME="" # Specify the adapter's name(a user defined alias).
docker run \
--gpus $GPU_ENUMERATION \
-p 8000:8000 \
-v $ADAPTER_DIR:/adapter \
-e FRIENDLI_CONTAINER_SECRET=$FRIENDLI_CONTAINER_SECRET \
$FRIENDLI_CONTAINER_IMAGE \
--hf-model-name $HF_BASE_MODEL_NAME \
--adapter-model $ADAPTER_NAME:/adapter \
[LAUNCH_OPTIONS]
You can find available options for [LAUNCH_OPTIONS] at Running Friendli Container: Launch Options.
If you want to launch with several adapters, you can use --adapter-model with comma-separated string.
(e.g. --adapter-model adapter_name_0:adapter_ckpt_0,adapter_name1:adapter_ckpt_1)
If tokenizer_config.json file is in an adapter checkpoint path, the engine uses a different chat template in tokenizer_config.json.
Example: Llama 2 7B Chat + LoRA Adapter
This is an example that runs meta-llama/Llama-2-7b-chat-hf with FinGPT/fingpt-forecaster_dow30_llama2-7b_lora adapter model.
export ADAPTER_DIR=/tmp/adapter
huggingface-cli download FinGPT/fingpt-forecaster_dow30_llama2-7b_lora --include "adapter_model.safetensors" "adapter_config.json" --local-dir $ADAPTER_DIR/model1
docker run \
--gpus '"device=0"' \
-p 8000:8000 \
-v $ADAPTER_DIR:/adapter \
-e FRIENDLI_CONTAINER_SECRET="YOUR CONTAINER SECRET" \
registry.friendli.ai/trial \
--hf-model-name meta-llama/Llama-2-7b-chat-hf \
--adapter-model adapter-model-name:/adapter
Sending Request to Specific Adapter
You can generate an inference result from a specific adapter model by specifying model in the body of an inference request.
For example, assuming you set the launch option of --adpater-model to "adapter-model-name:\<adapter-path>", you can send a request to the adapter model as follows.
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{
"prompt": "Python is a language",
"model": "adapter-model-name"
}' \
http://0.0.0.0:8000/v1/completions
Sending Request to the Base Model
If you omit the model field in your request, the base model will be used for generating an inference request.
You can send a request to the base model as shown below.
curl \
-X POST \
-H "Content-Type: application/json" \
-d '{
"prompt": "Python is a language",
}' \
http://0.0.0.0:8000/v1/completions
Limitations
- We only support models compatible with
peft. - Base model checkpoint and adapter model checkpoint should have the same datatype.
- When serving multiple adapters simultaneously, each adapter model should have the same target modules. In Hugging Face, the target modules are listed at
adapter_config.json.