QuickStart: Friendli Container Trial
Introduction
Friendli Container enables you to efficiently deploy LLMs of your choice on your infrastructure. With Friendli Container, you can perform high-speed LLM inferencing in a secure and private environment.
This tutorial will guide you through the process of running a Friendli Container for your LLM.
Prerequisites
- Hardware Requirements: Friendli Container currently only targets x86_64 architecture and supports NVIDIA GPUs, so please prepare proper GPUs and a compatible driver by referring to our required CUDA compatibility guide.
- Software Requirements: Your machine should be able to run containers with the NVIDIA container toolkit. In this tutorial, we will use Docker as container runtime and make use of Docker Compose.
- Model Compatibility: If your model is in a safetensors format, which is compatible with Hugging Face transformers, you can serve the model directly with the Friendli Container. Please check our Model library for the non-exhaustive list of supported models.
This tutorial assumes that your model of choice is uploaded to Hugging Face and you have access to it. If the model is gated or private, you need to prepare a Hugging Face Access Token.
Getting Access to Friendli Container
Activate your Free Trial
- Sign up for Friendli Suite.
- In the 'Friendli Container' section, click the 'Start free trial' button.
Now you can use Friendli Containers free of charge during the trial period.
Get Access to the Container Registry
PAT (Personal Access Token) is a user credential that is required for logging into our container registry.
- Go to User Settings > Tokens and click 'Create token'.
- Save the token you just created.
Prepare your Container Secret
Container secret is a secret code that is used to activate Friendli Container. You should pass the container secret as an environment variable to run the container image.
- Go to Container > Container Secrets and click 'Create secret'.
- Save the secret you just created.
🔑 Secret Rotation
You can rotate the container secret for security reasons. If you rotate the container secret, a new secret will be created and the previous secret will be automatically revoked in 30 minutes.
Running Friendli Container
Pull the Friendli Container Image
Log in to the container registry using the email address for your Friendli Suite account and the PAT (Personal Access Token).
export FRIENDLI_EMAIL="YOUR ACCOUNT EMAIL ADDRESS"
export FRIENDLI_PAT="YOUR PERSONAL ACCESS TOKEN"
docker login registry.friendli.ai -u $FRIENDLI_EMAIL -p $FRIENDLI_PATPull the image.
docker pull registry.friendli.ai/trial
Run Friendli Container with a HuggingFace Model
Clone our container resource git repository.
git clone https://github.com/friendliai/container-resource
cd container-resource/quickstart/docker-composeSet up environment variables.
export HF_MODEL_NAME="<...>" # Hugging Face model name (e.g., "meta-llama/Meta-Llama-3-8B-Instruct")
export FRIENDLI_CONTAINER_SECRET="<...>" # Friendli container secretIf your model is a private or gated one, you also need to provide HuggingFace Access Token.
export HF_TOKEN="<...>" # HuggingFace Access TokenLaunch the Friendli Container.
docker compose up -d
By default, the container will listen for inference requests at TCP port 8000 and a Grafana service will be available at TCP port 3000. You can change the designated ports using the following environment variables. For example, if you want to use TCP port 8001 and port 3001 for Grafana, execute the command below.
export FRIENDLI_PORT="8001"
export FRIENDLI_GRAFANA_PORT="3001"
Even though the machine has multiple GPUs, the container will make use of only one GPU, specifically the first GPU (device_ids: ['0']).
You can edit docker-compose.yaml to change what GPU device the container will use.
The downloaded HuggingFace model will be cached in the $HOME/.cache/huggingface directory.
You may want to clean up this directory after completing this tutorial.
Send Inference Requests
You can now send inference requests to the running container. For information on all parameters that can be used in an inference request, please refer to this document.
- Text Completion
- Chat Completion
curl -X POST http://127.0.0.1:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"prompt": "What makes a good leader?", "max_tokens": 30, "stream": true}'
curl -X POST http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "What makes a good leader?"}], "max_tokens": 30, "stream": true}'
Chat completion requests work only if the model's tokenizer config contains a chat_template.
Monitor using Grafana
Using your browser, open http://127.0.0.1:3000/d/friendli-engine, and login with username admin and password admin.
You can now access the dashboards showing useful engine metrics.
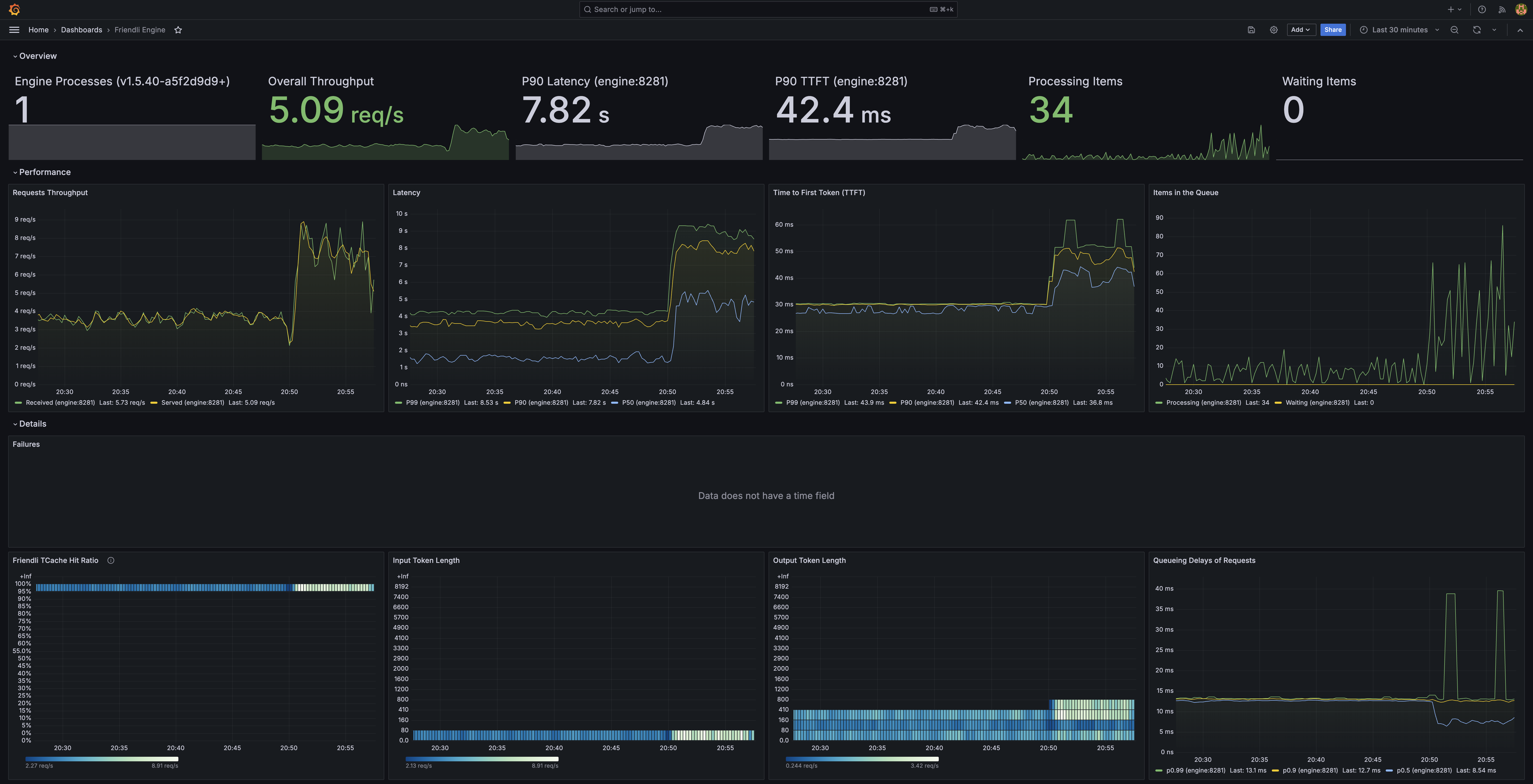
If you cannot open a browser directly in the GPU machine where the Friendli Container is running, you can use SSH to forward requests from the browser running on your PC to the GPU machine.
# Change these variables to match your environment.
LOCAL_GRAFANA_PORT=3000 # The number of the port in your PC.
FRIENDLI_GRAFANA_PORT=3000 # The number of the port in the GPU machine.
ssh "$GPU_MACHINE_ADDRESS" -L "$LOCAL_GRAFANA_PORT:127.0.0.1:$FRIENDLI_GRAFANA_PORT"
where $GPU_MACHINE_ADDRESS shall be replaced with the address of the GPU machine.
You may also want to use -l login_name or -p port options to connect to the GPU machine using SSH.
Then using your browser on the PC, open http://127.0.0.1:$LOCAL_GRAFANA_PORT/d/friendli-engine.
Going Further
Congratulations! You can now serve your LLM of choice using your hardware, with the power of the most efficient LLM serving engine on the planet. The following topics will help you go further through your AI endeavors.
- Multi-GPU Serving: Although this tutorial is limited to using only one GPU, Friendli Container supports tensor parallelism and pipeline parallelism for multi-GPU inference. Check Multi-GPU Serving for more information.
- Serving Multi-LoRA Models: You can deploy multiple customized LLMs without additional GPU resources. See Serving Multi-LoRA Models to learn how to launch the container with your adapters.
- Serving AWQ Models: Running quantized models requires an additional step of execution policy search. See Serving AWQ Models to learn how to create an inference endpoint for AWQ models.
- Serving MoE Models: Running MoE (Mixture of Experts) models requires an additional step of execution policy search. See Serving MoE Models to learn how to create an inference endpoint for MoE models.
If you are stuck or need help going through this tutorial, please ask for support by sending an email to Support.